
The Final Result
It’s a double self-knockout! Both contenders have comically punched themselves in the face and are currently being stretchered out of the arena. No score draw. Everyone loses.
…obviously, we can’t end things there on such a low note.
In fact, if you’ve been paying close attention up to here, you probably already know the real solution. Which is…
Completely rewrite your system as an elegantly decomposed set of microservices. Take up the anti-mock position in each one and simply put up with the now watered down deficiencies of that testing approach.
Thanks for reading and I’ll see you next time!
…I am, of course, completely, mostly half-joking.
Thankfully, like nearly all other classic dichotomies out there, Mocks vs No Mocks is also a fraud.
We could toss a coin and pick from one of these two fatally flawed unit testing philosophies. Instead, why not learn from their strengths and weaknesses and go for something that might actually work:
Enjoying Mocks Responsibly
Hand our old contenders the smelling salts, it’s time to take a look at their strengths:
- Building assertions around mocks helps to document and protect design decisions
- Building assertions around state helps to document and protect features
How about we alternate our mocking strategies to maximise the benefits of unit testing within our application? Mockist tests can help secure important design decisions and in doing so clear them out of the way for our state-based tests. Something like this:
- React examples
- OO examples (coming soon)
“Looks like you’ve got mocks in your mock-less, state-based tests…”
Actually, they’re stubs: the pre-canned, less-asserted-upon, cousins of mocks. I’ve left it comically late in this article to provide accurate descriptions of their differences, but if this important distinction is new to you, try here and maybe here.
“What’s the definition of an ‘important design decision’? And don’t we want to secure all design decisions anyway?”
We do, that’s why we use GitHub, pull requests and version control. Every single design decision is gated, documented and protected against surprise alterations.
On top of that, we use the decoupling superpower of mockist tests deliberately and responsibly to protect important design decisions.
“Which are..?!”
All the unit testing blogs in the world won’t help us with one, but good architecture blogs might.
If we think about Clean Architecture or Hexagonal Architecture or Onion Architecture, they all put a huge emphasis on layering and not letting certain concepts bleed between those layers. Likewise, if we think about Domain Driven Design, a key tenant is not letting certain concepts bleed between business domains.
It’s at these boundaries that we should use mocks.
Mocks will help our use cases stay agnostic of transport concerns and vice-versa. They will also keep use cases within sibling domains ignorant of each other’s implementation details – decoupled from the different forces that drive change in each one respectively.
It’s not all about detachment though, what they do couple us to (and importantly help preserve) are the behavioural expectations across these boundaries.
With this approach, if a developer has chosen to use a mock in a certain test it is because we are either at an architecture layer boundary or a domain boundary. Done consistently, these mock-orientated unit tests will group together and build the aforementioned clearings for state based unit tests which can then protect features.
Let’s see if we can visualise this layering of state based and mock based units:
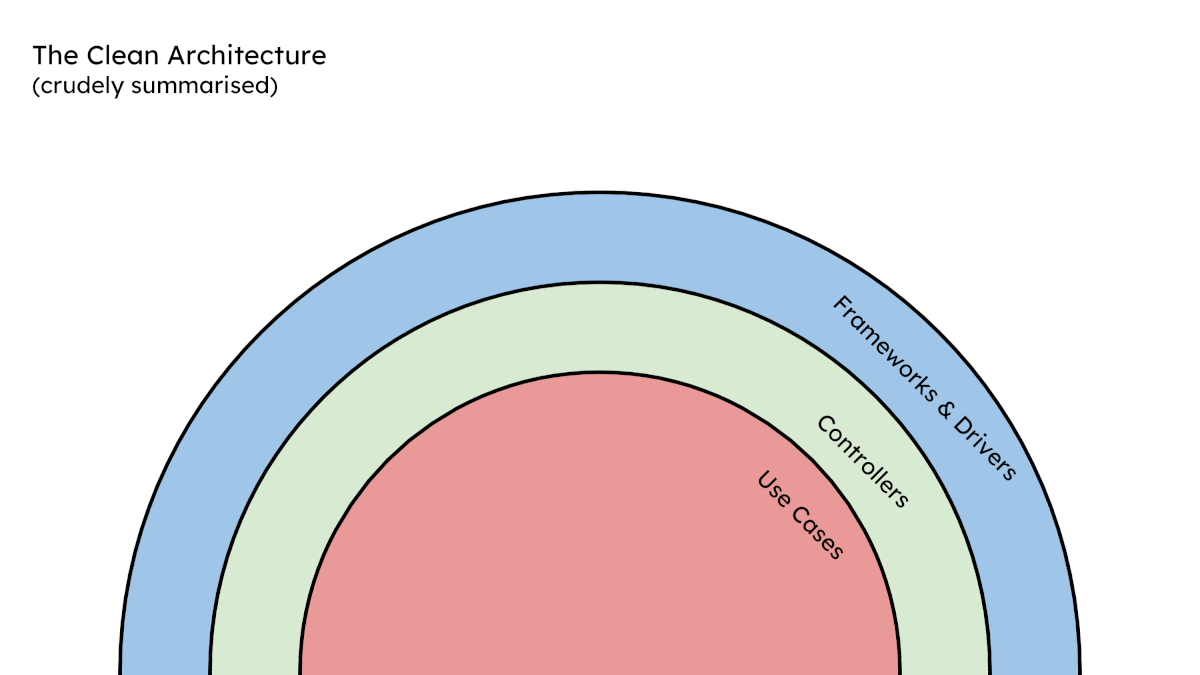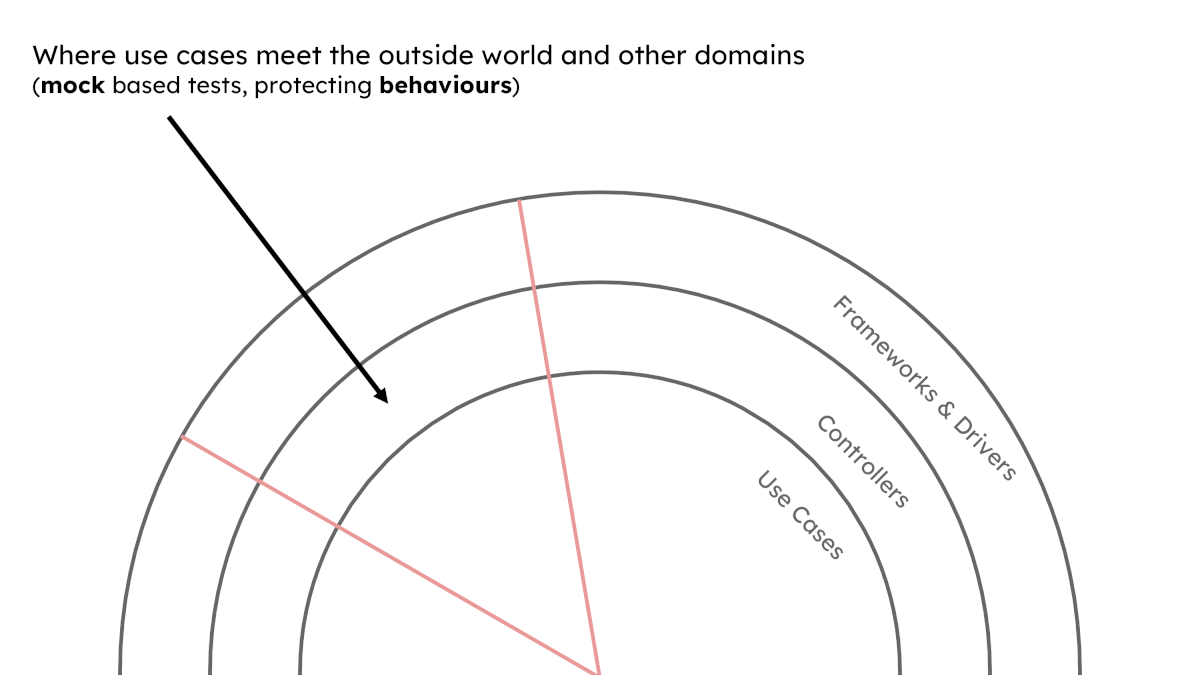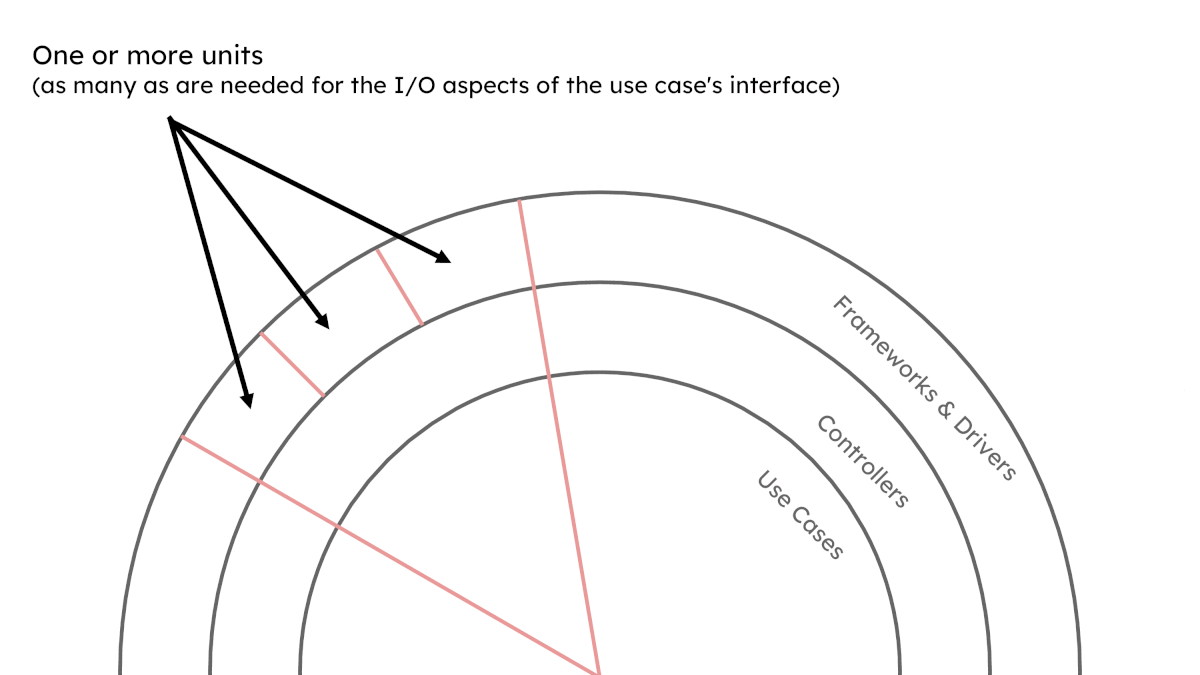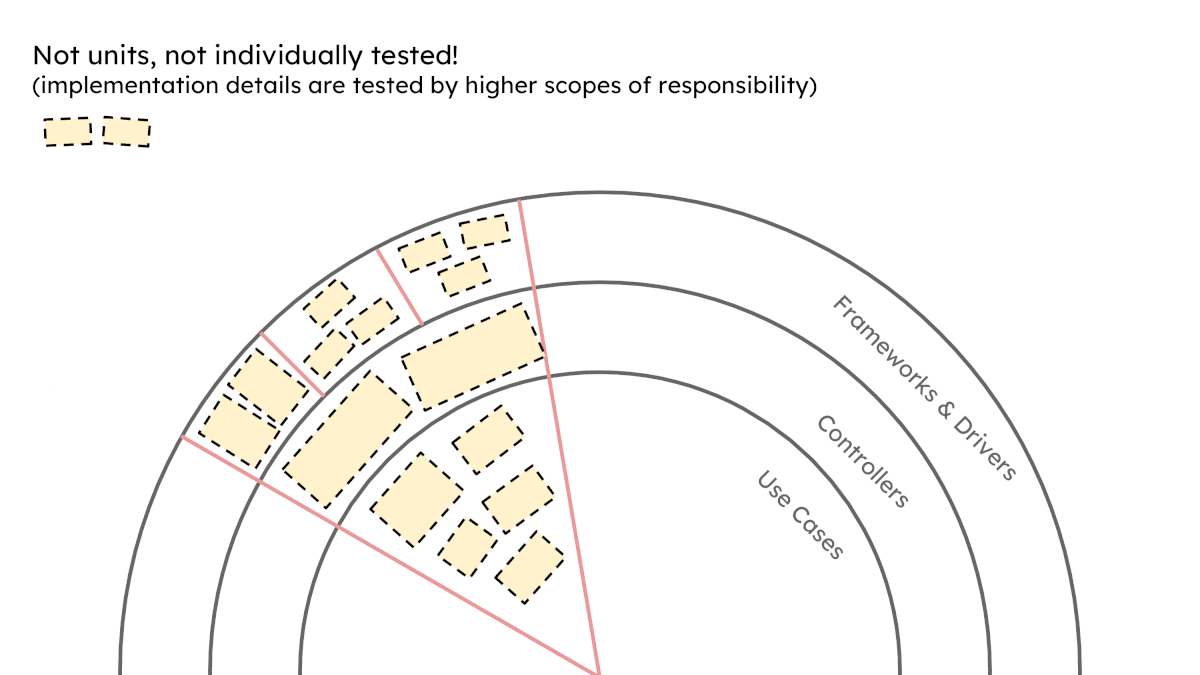
(I’ll ask our wonderful artist to make this pretty once I’m confident that it’s providing some actual value 😅)
Now, before I get too comfortable sat up on my high horse, it’s only fair that this third strategy quickly runs the same gamut as the other two.
So…
How big or small is a ‘unit’?
It’s the size of your current best, legible, working implementation of its singular responsibility.
…sounds fancy, but what the hell does that mean in practice?
Clean Architecture and DDD are imposing hard boundaries in this world. No code can have a mix of transport/anti-corruption/use case responsibilities, it must pick one. No code can have that responsibility across multiple domains, it must sit within one.
That’s not to say the same layers in the different domains can’t make use of the same domain agnostic libraries or dependencies – they can and almost certainly should.
In practice, we end up with neat little boxes of singular responsibility: “X use case within the Products domain”, “Y to Z, anti-corruption layer for the Catalogue domain” and so on. Our ‘unit’ is however much code we require to fill each of those individual boxes of responsibility.
“Hold on…
…what if that’s too big?” It’s a good question and one I’ll largely side-step for now and come back to in a future article. For now I’ll just say that would typically hint at violations of the single responsibility principal, missing levels of abstraction or anaemic, “do everything” APIs.
Ease of Use: 6/10
If you have a grasp of the strategy’s “when to mock” rule and a good understanding (and belief in) DDD, plus some form of layered architecture – then it should be pretty easy.
As you move through your code you’ll find some units aggregating concerns across layers and domains which are better suited to mock based testing. Then you’ll find patches that only seem to compose fellow classes or functions which can be tested in state-based fashion, mock-free.
You’ll also find some units that seem to do a bit of both, breaking your DDD and/or architecture rules. Refactor these ugly spots away and then apply the right mocking strategy accordingly.
However, if a developer does not have those prerequisites they will need plenty of guidance from those who do. Maybe repo structures and automated tools can provide basic guard rails, but those things alone won’t be enough to stop greener developers veering off course.
In this world TDD is back and really wonderfully paint-by-numbers, but I’ll leave that explanation to someone who actually knows what they’re talking about.
10 out of 10 from pro-mocks… plus 2 out of 10 from anti-mocks… divided that by 2…
Looks like my maths is finally getting better: 6 out of 10 for Ease of Use this time round.
Stability: 10/10
Same as each time before, our stability score is based on the tests’ ability to not fail for anything other than a genuine feature regression. Typical false positives here have come from code refactoring and the addition of new features – both of which are completely essential for any long-lived system.
What happens when we refactor code protected by our mock-less (though stub reliant) use case tests? Nothing. The only failures you’ll see here are genuine.
Alter the test itself, update its assertion to expect a different flavour of feature, and obviously it will fail – but that’s what we want, you haven’t implemented that new feature flavour yet.
What happens when we refactor aggregating code protected by mocks? Again nothing. If you’ve found better ways for that unit to manage the interactions of its different architecture layers or the domains it mediates for – go for it.
Make changes to which other layers or domains it talks to or how it talks to them, expect failures. However, if you’ve been wise enough to add these new architectural or DDD requirements to your tests first, expect passes.
We’re on firm ground now and it feels like a perfect 10.
Tests as Documentation: 9/10
With all the layering concerns pushed out of the way of our state based tests, feature definitions are clear and focused. Much like in our anti-mock world, we’ve brought the very reasons for our code’s existence to the fore.
However, unlike in that world, it’s not buried beneath an unfavourable signal to noise ratio.
A new developer to the team wants to know what features this application embodies? Send them to the tests for your use cases.
Beyond those use case tests, they’ll be met with our mock-using aggregators. These don’t document features, but just as importantly they document our architectural and domain boundaries:
- “Our transport layer ends here”
- “We consider Products and Catalogue separate domain concepts that meet at this boundary”
- “Who cares what a database is? Something just needs to adhere to my Use Case’s interface”
In this world, mocks have finally regained their meaning. Yusssss, 9 out of 10.
Regression Prevention: 8/10
Ah crap, I kinda stole all this section’s thunder while making my case for Stability. So, rather than rehashing all that again, let’s focus on an interesting difference with the anti-mock world: we’ve dropped down a score point.
Why? Any time we use mocks we inevitably trade decoupling for a risk of behavioural drift. Once again, our tests only truly prevent regression if…
“each unit behaves exactly as all mocks which impersonate them suggest they do”
And maybe they do, maybe they don’t. Maybe one domain expects a second domain to reflect changes immediately, but that second domain uses eventual consistency. Maybe a “get all products” command used to return draft products, but now it doesn’t.
It’s a calculated tradeoff to help get our signal to noise ratio down, gain a whole heap of stability and keep the strategy easy enough to implement. For that reason, we’ll have to make do with 8 out of 10 here.
Overall Score: 8/10
By taking the best of both the pro-mock and anti-mock worlds, applying practices from each specifically (and not just blindly) to our application, we’ve ended up with unit tests which are:
- Easy(ish) to implement
- Very stable
- Very descriptive
- Protects architectural boundaries
- Protects domain boundaries
- And prevent nearly all regression
Who could ask for more? Well, “easier”, sure. But once that learning curve is out of the way, we’ve got unit tests that will make our developers, our product owners and our CI/CD pipelines very happy.
More importantly, with many fewer regressions getting out to production, we should be keeping our clients (and thus our bank accounts) very happy too.
The bad news with this third strategy is that it requires developers working on the application to have an understanding of DDD and software architecture best practices.
The great thing about this strategy is – that’s also the good news.
“Hold on…
…I’m not using any form of clean architecture and/or DDD in my project.” If you’re working on anything long lived, with multiple developers and expectations of growth… you might wanna look into those methodologies.
All is not lost though, you just have a bit of a longer road ahead of you before you can benefit at unit test level. It’s worthy of its own mini article – and this one is already long enough. Suffice to say, sometimes you’ve got to up the testing pyramid to come back down again.
The Final, Final Result
Blindly using one tool for the job – mocking as little, or as much, as possible – just doesn’t pay off. If you want the best unit testing strategy, you’ll need to understand the why as well as the how.
Inevitably, our winner is:
Enjoying Mocks Responsibly 🥳
Afterword
Who’d have guessed it? The strategy the author was championing has come out on top and by a considerable margin. Hopefully, I’ve kept myself honest and have referenced enough sensible sources to back my position, but let me know where I’ve taken a leap or two too far.
Obviously, real world applications will live somewhere on a spectrum of mockist and anti-mock, clean architecture and spaghetti, DDD and nonsense, which I could not fully represent here. Hopefully my more extreme examples have laid the groundwork for your own, more realistic, comparisons with Enjoying Mocks Responsibly.
I certainly wouldn’t have been able to write this article without having first watched the talk Does TDD Really Lead to Good Design? by Sandro Mancuso. His talk crystallised a lot of concepts that I’d vaguely struggled with within development and testing over my career.
Most of the good ideas here are his, I take full credit for all the crap ones.